
KUDA: Keypoints to Unify Dynamics Learning and Visual Prompting for Open-Vocabulary Robotic Manipulation
ICRA 2025
Best Paper Finalist at CoRL LangRob Workshop, 2024 [PDF] [Project] [Code]
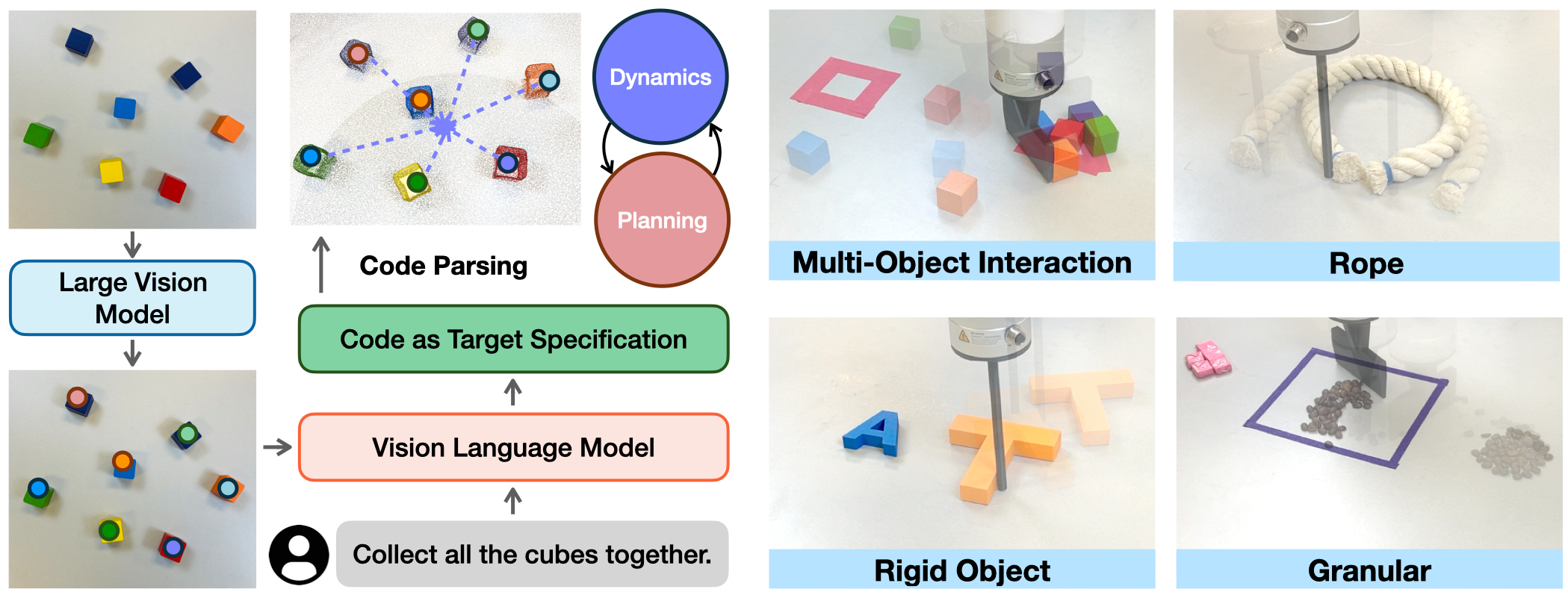
KUDA is an open-vocabulary manipulation system that unifies the visual prompting of vision language models (VLMs) and dynamics modeling with keypoints.